近年来,能清晰说明诊疗依据的医疗人工智能已用于辅助临床决策,但这类技术的发展受限于关键瓶颈——详细记录医生诊疗思考过程的临床诊疗思路链数据太过稀缺。这类数据能完整展现从分析病情到制定方案的推理路径,是打造可信医疗AI的核心基础,可人工整理不仅成本高,效率还低,这在很大程度上阻碍了辅助生殖技术(ART)领域医疗AI的进步。为破解这一难题,研究团队尝试用大型语言模型批量生成这类临床诊疗思路链,本研究专门聚焦辅助生殖场景,重点验证模型生成内容的临床靠谱程度,以及不同提示方法对诊疗建议质量的影响,核心围绕辅助生殖的诊疗方案选择与用药决策展开评估。
Liu D, Long Y, Zuoqiu S, et al. Reliability of Large Language Model Generated Clinical Reasoning in Assisted Reproductive Technology: Blinded Comparative Evaluation Study. J Med Internet Res. 2026;28:e85206. Published 2026 Jan 8. doi:10.2196/85206
双重实验设计:层层递进探究核心问题
本研究以“找到最优提示方法”和“验证诊疗推理是否靠谱”为核心目标,设计了逻辑严密的实验体系,通过统一模型参数、多维度评估的方式,形成“对比提示方法→验证结果可信度”的完整分析框架。
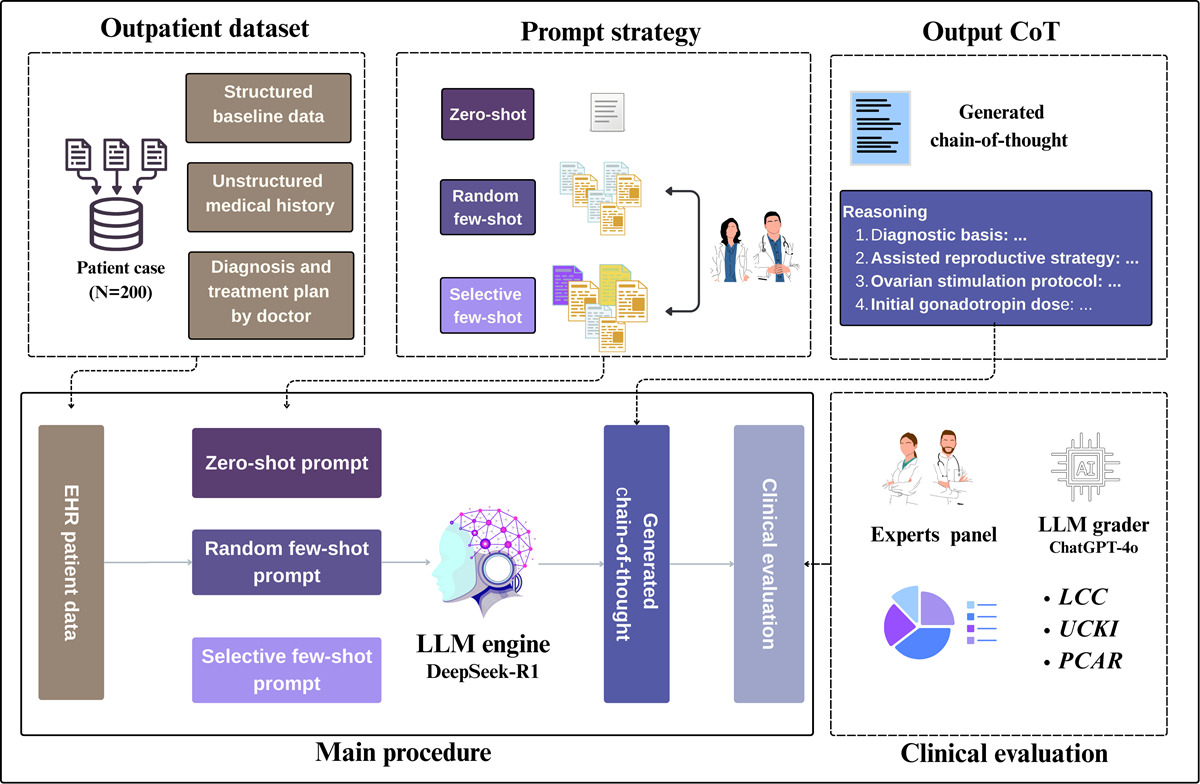
实验一重点对比三种不同提示方法的效果。研究选用推理能力较强的大型语言模型DeepSeek-R1-671B,以200例真实辅助生殖病例为研究基础,这些病例涵盖IVF、ICSI、PGT三大类及常见亚型,临床数据完整。第一种提示方法是无参考案例法:只给模型下达诊疗任务和患者病例,看模型仅凭自身能力给出的诊疗建议质量;第二种是随机参考案例法:在任务和病例外,随机加5个简单的IVF诊疗案例当参考,观察普通参考案例的作用;第三种是精选参考案例法:专门筛选6个覆盖所有主要辅助生殖类型的优质诊疗案例当参考,既保证案例的临床专业性,又兼顾场景全面性。要求模型不仅给出诊疗建议,同时给出详细的推理思路,对模型的回答从推理逻辑通顺度、关键病情信息利用率、诊疗建议临床准确性三个维度打分评估。
实验二用来验证评估结果的可靠性。研究邀请2名拥有10年以上辅助生殖临床经验的医生,采用盲法独立打分,评分前统一评价标准,避免主观偏见;同时用GPT-4o模型作为AI评估工具,按相同标准打分,对比医生与AI评估结果的差异,确保对诊疗建议质量的评判客观可信。
关键研究结果:精选参考案例策略脱颖而出
三种提示方法对比:优质参考案例是提升质量的关键
三种方法中,精选参考案例法表现最优,在推理逻辑通顺度、关键病情信息利用率、诊疗建议临床准确性三项核心指标上,平均分分别达4.56、4.66、4.18,显著优于另外两种方法(P<0.001)。这一优势在IVF、ICSI、PGT各类病例中都很明显,尤其在病情复杂的PGT病例中,优势更突出。
随机参考案例法仅在推理逻辑和信息利用上略好于无参考案例法,但核心的诊疗建议临床准确性两者差别不大(3.91 vs 3.85);无参考案例法整体得分最低,生成的诊疗思路常出现关键病情信息遗漏、推理过程不完整的问题。
病例解析:暴露低质量策略缺陷
以复杂的单基因病PGT(PGT-M)病例为例,无参考案例法和随机参考案例法生成的诊疗思路存在明显临床漏洞:没完整分析患者不孕诊断背景,在是否选用ICSI技术时,忽略了PGT病例需避免胚胎基因污染的特殊要求;选择卵巢刺激方案时只强调安全性,没结合患者AMH偏低、首次促排卵的个体情况。而精选参考案例法生成的诊疗思路,临床逻辑完整,上述问题均未出现,与医生临床思维高度契合。
评估对比:AI 暂无法替代人类专家
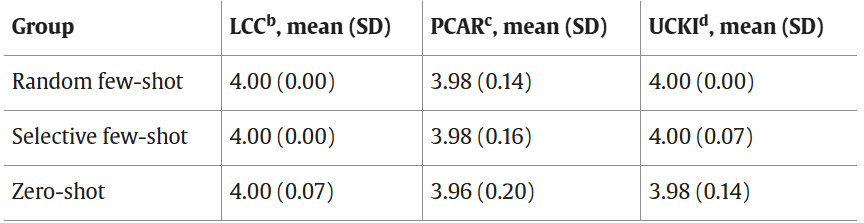
在评估一致性方面,GPT-4o 对不同提示策略的评分集中在 3.96–4.00 区间,未能区分出策略间的显著差异,提示其在识别具有临床意义的推理质量差别方面存在一定局限。相比之下,人类专家之间的评分分歧率最高为 12%,相邻一致率达到 88%–100%,显示出较高的一致性,也体现了领域专家评估在当前阶段的重要作用。

研究创新与局限:客观看待科学价值
核心创新点
研究提出辅助生殖领域生成高质量诊疗思路链的关键提示原则——参考案例需同时满足临床专业性(贴合诊疗指南,推理有依据)和场景全面性(覆盖所有主要辅助生殖类型),证实提示方法的效果取决于案例质量和覆盖度,而非单纯数量。同时通过医生与AI并行评估,为临床诊疗思路的自动化评估提供了实用参考。
不可忽视的局限性
需要指出的是,本研究基于单中心病例数据,并仅使用单一生成模型,结论在不同数据来源和模型架构下的适用性仍需进一步验证。此外,精选案例参考法与随机案例参考法在示例数量和深度方面存在差异,相关因素尚无法完全区分;部分亚型病例数量较少,可能影响统计稳定性;AI 评估器的表现也可能受到提示设计和模型能力的影响。
临床意义与未来展望:为生殖医学 AI 指明方向
临床应用价值
经过科学设计的精选案例参考方法,能让大型语言模型生成高质量的辅助生殖诊疗思路链,有效缓解优质临床推理数据稀缺的难题。这类合成数据未来有望用于训练优化临床决策支持系统,帮助医生快速整合患者信息、精准评估诊疗方案与用药策略,尤其能为基层医疗机构提供支持,提升辅助生殖诊疗的规范化水平。同时研究也提醒,临床中需谨慎使用自动化评估工具,避免过度依赖。
未来研究方向
后续将开展多中心、多模型验证,通过专项实验明确案例数量、专业深度、场景覆盖度各自的影响;结合权威辅助生殖诊疗指南,优化提示方法进一步提升模型推理的临床准确性;针对临床诊疗思路的评估需求,开发更灵敏的自动化评估工具,完善临床AI评估体系。