在 IVF 实践中,我们已经能够通过 PGT 识别染色体异常和部分基因突变,但仍有相当一部分胚胎发育异常或早期流产病例,无法用染色体或编码区变异完全解释。越来越多研究提示,问题可能涉及非编码调控区域及基因表达调控层面的异常。然而,在人类早期胚胎中,由于样本极其珍贵,难以开展完整的多组学检测,这限制了对调控机制的深入分析。
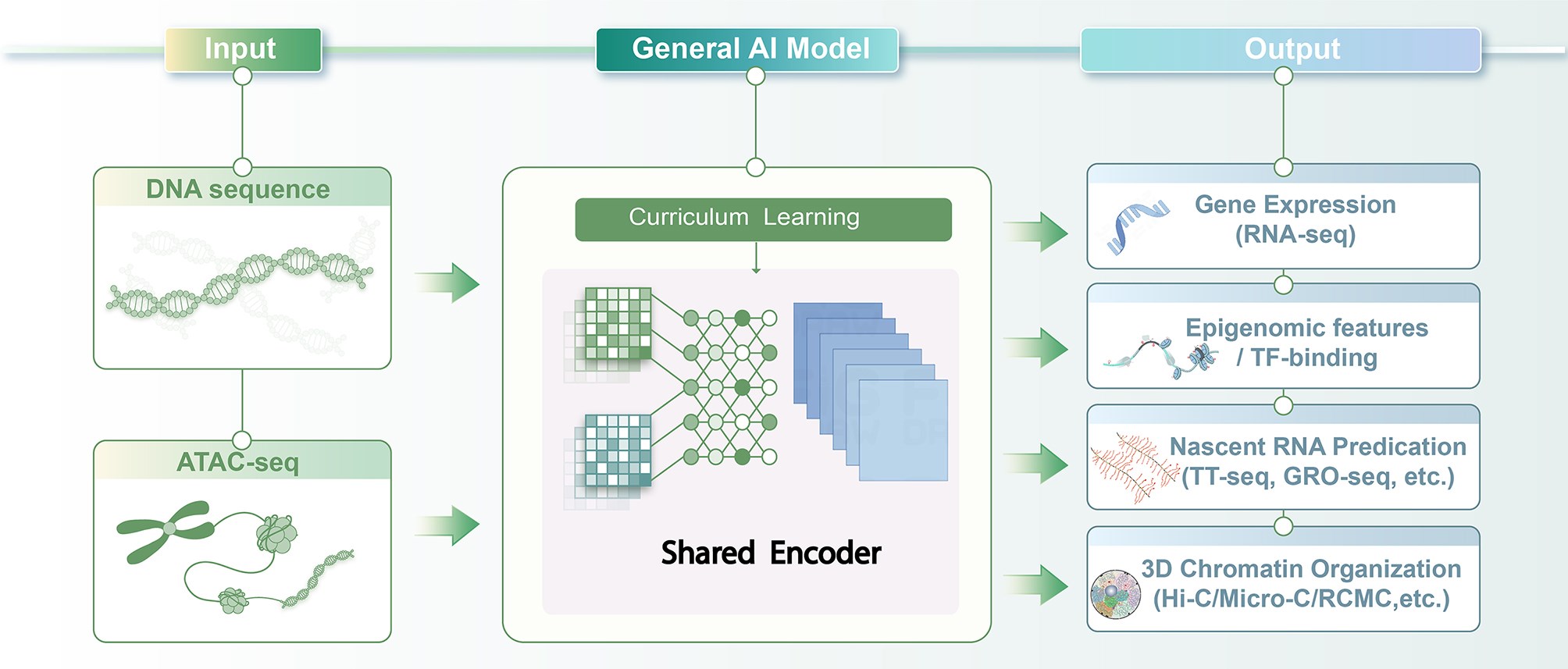
本次介绍的论文提出了一种多任务 AI 模型,仅依赖 DNA 序列与 ATAC-seq(记录染色质开放状态的测序方法),即可预测多种基因调控特征,为未来将调控异常纳入 PGT 补充分析框架提供了理论基础。不过,该模型仍依赖开放染色质信息输入,其在真实早期胚胎体系中的泛化能力与分辨率上限仍有待进一步验证,因此更适合作为实验补充工具,而非替代多组学实验。
Zhang Z, Bao X, Jiang L, et al. Developing a general AI model for integrating diverse genomic modalities and comprehensive genomic knowledge. Nucleic Acids Res. 2025;53(21):gkaf1269. doi:10.1093/nar/gkaf1269
实验设计
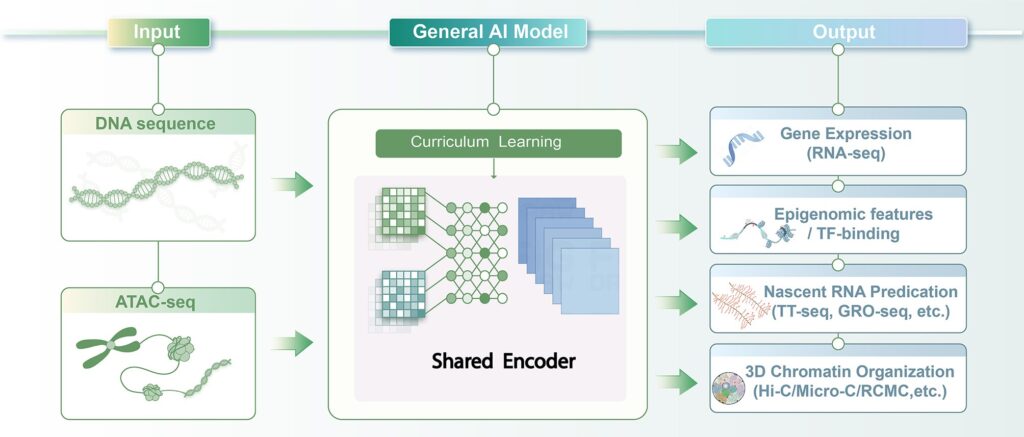
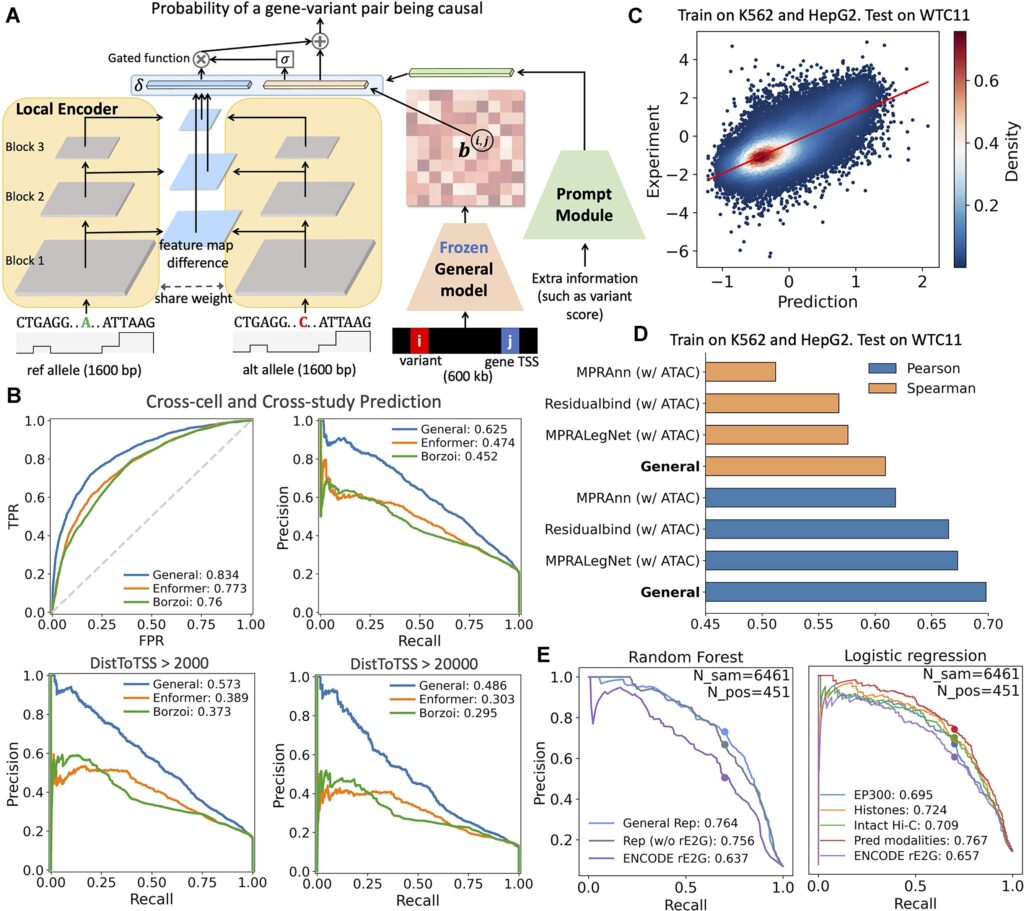
该研究以“通用性”和“数据可获得性”为核心目标,在尽量降低实验输入要求的前提下,保留对多种调控特征的预测能力。模型仅需两类信息:DNA 序列以及 ATAC-seq 数据(用于记录哪些 DNA 区域处于开放状态)。在此基础上,模型通过统一框架同时预测基因表达、调控区域活性及染色质结构等多种特征,从而减少对高成本多组学实验的依赖。
在训练策略上,研究团队采用由易到难的分阶段训练方式,使模型先学习相对直接的表达模式,再逐步扩展到更复杂的结构预测,以提高稳定性。同时,模型整合了多种细胞和组织数据,并引入适应数据缺失情况的训练策略,使其在不同生物背景下仍保持较好的泛化能力。
在跨物种应用方面,研究团队将训练完成的人类模型迁移至小鼠基因组,通过微调适配物种差异,构建出小鼠版本的通用 AI 模型。即便在部分小鼠数据有限的情况下,该模型仍能维持较高预测准确度,为模式动物研究与人类发育机制之间的比较与转化提供了计算层面的桥梁。
研究结果
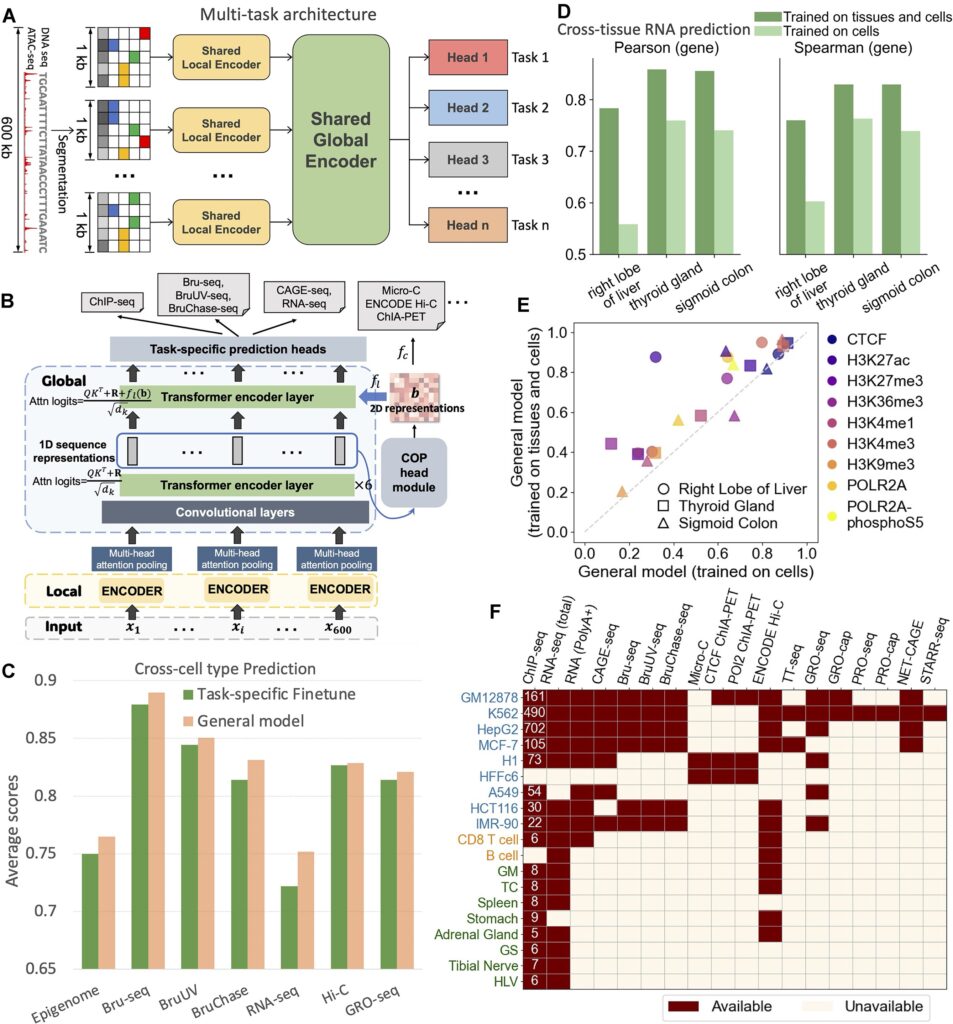
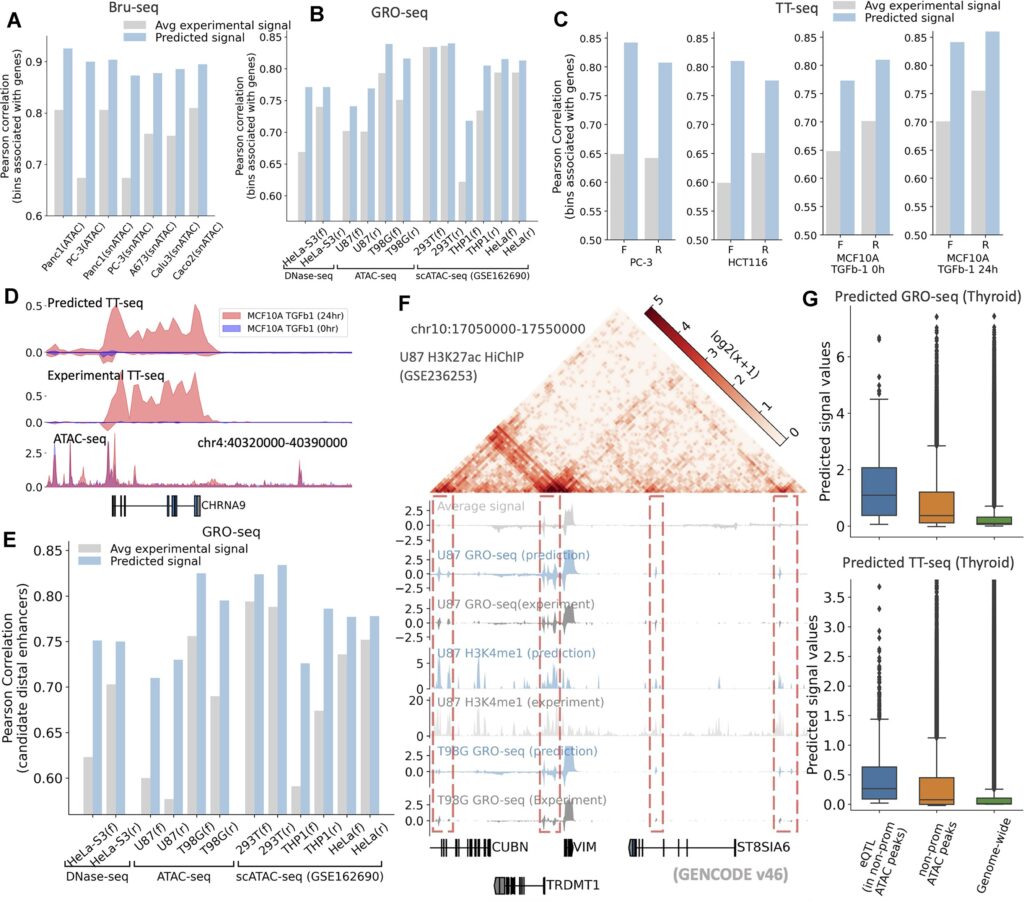
在人类数据测试中,该模型仅依赖 DNA 序列与 ATAC-seq 数据(用于记录哪些 DNA 片段处于开放、可能正在发挥作用状态的测序信息),即可较为准确地预测基因表达水平及多种调控特征。在基因表达预测任务中,其与真实 RNA 测序结果的 Spearman 相关系数平均超过 0.75。在多类核心任务中,整体表现达到或接近专门针对单一任务优化模型的水平。即便在未参与训练的组织类型中,模型仍能保持较高预测精度,显示出一定泛化能力。
在非编码区功能预测方面,模型表现尤为突出。在 13 种新细胞类型中,对影响基因表达的遗传变异进行分类测试时,AUC 稳定在 0.82 以上,优于既有主流预测模型,尤其在远端调控区域的分析中更具优势。这一结果提示,该模型在识别传统染色体或编码区检测难以覆盖的调控异常方面具有潜在价值。
在小鼠发育模型验证中,基于单细胞染色质开放数据推测的基因表达谱,与实验单细胞 RNA 测序结果的 Pearson 相关系数最高可达 0.75。在高分辨率染色质空间结构预测中,相关系数达到 0.67,显示其在不同物种和发育场景中仍具较稳定的预测能力。
创新与局限
这项研究的核心创新,在于把原本需要分别建立的多个预测模型整合到一个系统中。该研究则通过一个统一模型,在有限实验数据的基础上,同时推测这些不同层面的信息。这种做法更接近真实生物系统中“多层级共同调控”的状态,也更适合样本数量有限的研究场景。此外,研究还设计了分阶段训练和不完整数据训练的方法,使模型能够适应现实中数据不齐全、不均衡的情况,并尝试在人类与小鼠之间进行模型迁移,为利用动物数据辅助理解人类发育机制提供了技术路径。
然而,模型仍存在一定局限。对于长度较短、作用精细的调控区域,模型的定位精度仍然有限;对于样本较少或发育阶段特殊的细胞类型,预测结果的稳定性还有待进一步验证。同时模型依赖 ATAC-seq 数据作为关键输入,在缺乏开放染色质信息时难以独立运行。此外,部分染色质接触图模态的预测提升幅度仍低于其他任务,提示三维结构建模仍有进一步优化空间。
临床意义和展望
从应用角度来看,该模型的核心价值在于其“信息补全”能力。在临床胚胎研究中,样本十分珍贵,往往难以在同一枚胚胎上开展多组学检测。该模型通过少量可获得的数据,推测多个层级的调控信息,相当于在不增加取材或实验负担的前提下,提高单一样本所能提供的信息密度。这种能力有助于从调控层面理解胚胎发育潜能差异,为探索发育异常的分子基础提供新的分析工具。
在辅助生殖领域,当前 PGT主要聚焦染色体数目异常及部分已知基因突变,而大量调控信息位于非编码区域。该模型对非编码调控功能的预测能力,为未来在染色体正常但发育结局不理想的情况下,提供一种潜在的分析补充路径,用于帮助解释部分现有检测难以覆盖的调控异常问题。
展望未来,这类模型若要在胚胎学研究甚至临床辅助决策中发挥更稳定的支撑作用,仍需提升对精细调控区域的解析能力,扩大不同发育阶段与细胞类型的数据覆盖范围,并加强与实验验证之间的闭环整合。随着人工智能与单细胞检测技术的持续融合,计算预测有望在假设生成与风险筛查阶段发挥更大作用,但其真正临床价值仍需通过长期、多中心数据验证来确立。