本次介绍的论文提出了一种创新的体外受精(IVF)胚胎评估基础模型——FEMI。该研究通过自监督学习从大量未标注的胚胎时差图像中提取通用特征,为多种临床任务提供强大的预训练基础。FEMI在倍性预测、囊胚质量评分等关键任务中表现出色,显著降低了对人工标注数据的依赖。然而,其数据来源主要集中在高资源中心,对中低收入地区和高龄患者的代表性不足,限制了模型在更广泛场景下的应用。
Rajendran, S., Rehani, E., Phu, W. et al. A foundational model for in vitro fertilization trained on 18 million time-lapse images. Nat Commun 16, 6235 (2025). https://doi.org/10.1038/s41467-025-61116-2

研究背景:传统胚胎评估的现实困境
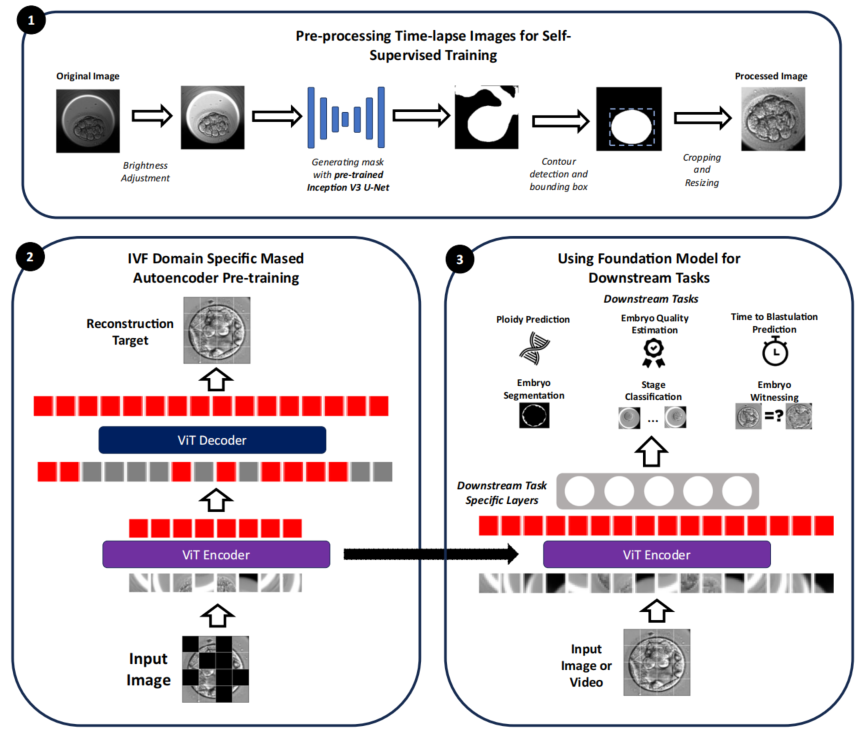
体外受精(IVF)成功率高度依赖胚胎筛选精度,但现有方法面临三重困境:PGT-A检测费用高昂且具侵入性,全球胚胎评分标准不统一导致胚胎学家主观判断差异显著,现有AI工具仅能解决单一任务且依赖大量人工标注数据,最终造成优质胚胎可能被误判,患者承受不必要的经济与情感负担。本研究将”基础模型”理念引入生殖医学,通过自监督学习让AI从1800万张未标注时差图像中自主掌握胚胎发育规律,再迁移至多个临床任务,目标是构建无创、标准化、可复用的胚胎评估体系。
研究方法:让机器先”看懂”胚胎
研究采用”先广泛观察,再专项训练”的两阶段策略构建基础模型。第一阶段,团队将近1800万张未经标注的时差图像(受精后85-112小时)用于”看图补全”训练——系统随机遮挡大部分区域,让AI根据可见部分推测完整胚胎形态,培养对胚胎形态的整体理解。第二阶段在预训练好的”观察系统”上增加轻量化输出模块,用数百至数千例标注数据训练AI完成具体判断(如评分或分类),并锁定基础系统参数、仅调整末端权重,既保留深度理解又防止小数据集过拟合。
为评估FEMI的真实性能,研究设置了多层次对照。首先与12种主流模型横向比较,包括传统监督模型(VGG16、ResNet101、EfficientNet等)、视频分析模型(MoViNet)以及IVF领域现有AI(STORK-A)。其次,与同样采用自监督学习的模型对比,以此检验医学领域预训练的实际增益。所有对比均在六大临床任务上统一使用相同数据集、相同评估指标,并采用四折交叉验证确保结果稳健。测试数据涵盖5个生殖中心(不同国家、设备型号、操作习惯),以此检验模型在多场景下的泛化能力。

研究结果:多项任务中表现良好
倍性预测在复杂型非整倍体识别中,视频+年龄输入达到85%准确率,单图模型在部分数据集亦超75%,为资源有限地区提供无创筛查可能。针对评分10-14分的低质量胚胎亚组,FEMI准确率67.7%,可解释性分析显示模型注意力集中在细胞边界清晰度、内细胞团致密程度、滋养层细胞均一性,与胚胎学家判断逻辑高度一致。囊胚质量评分对内细胞团的预测误差比现有模型降低45%,内细胞团评估主观性较强,FEMI的高精度表明机器可稳定学习较复杂的评判规则,视频输入在滋养层评分上优势突出,在高质量胚胎预测中误差不到1分,低质量胚胎误差2.04分,均优于所对比的EfficientNet-V2模型。
胚胎匹配在96-112小时跨度达90%以上F1分数,此前同类技术仅在105-110小时窄窗有效,时间窗放宽意味着即使胚胎移出培养箱较长时间,系统仍能可靠找回,降低临床操作心理压力与错误风险。囊胚发育时间预测误差约6小时,足以帮助胚胎学家预判次日重点观察对象,且时间预测误差小的胚胎往往发育节奏正常,与非整倍体风险呈负相关。胚胎区域分割虽训练数据仅274例,FEMI在透明带与滋养层分割精度上仍取得较好结果,Dice系数0.85-0.95,与医学图像分割专用模型MedSAM相当。阶段分类Top-2准确率90.8%,意味着第一或第二判断几乎总能命中真实阶段,这种模糊正确特性在实践中具有实用意义。

研究创新及局限
研究创新:FEMI是IVF领域较早尝试基础模型的研究,1800万张图像预训练的通用特征可迁移至所有任务,显著降低标注数据需求;视频动态分析在无创倍性预测中取得85%准确率,为资源有限地区提供PGT-A替代初筛可能;在5个不同国家、设备、操作习惯的数据集上均保持良好性能,显示出较好的泛化能力;质量评分与阶段分类采用回归而非分类,允许中间状态预测,更符合生物学本质。
现存局限:训练数据主要来自高资源中心,未覆盖中低收入地区不同培养条件,高龄患者数据不足可能影响极端年龄组预测稳定性;训练截止112小时,对第6/7天囊胚预测能力未验证,延迟囊胚可能为整倍体,需扩展时间窗;质量评分依赖胚胎学家主观判断为标准,模型可能复现偏见而非真理;注意力图虽显示关注区域,但综合决策逻辑仍是灰箱,需更精细的生物学解读。
临床意义及未来展望
本研究通过自监督学习构建的AI基础模型,为IVF胚胎评估提供了一种高效、无创且标准化的新方法。该模型在倍性预测、囊胚质量评分、胚胎核对等关键任务中展现出卓越性能,显著降低了对人工标注数据的依赖,同时在多中心数据集上表现出良好的泛化能力。这不仅有助于提高胚胎选择的准确性,还能减少因主观判断差异导致的误判,为患者提供更可靠的IVF治疗方案。在未来可以整合代谢组学和基因组学数据,构建数字胚胎孪生模型,推动IVF从经验医学迈向精准医学。