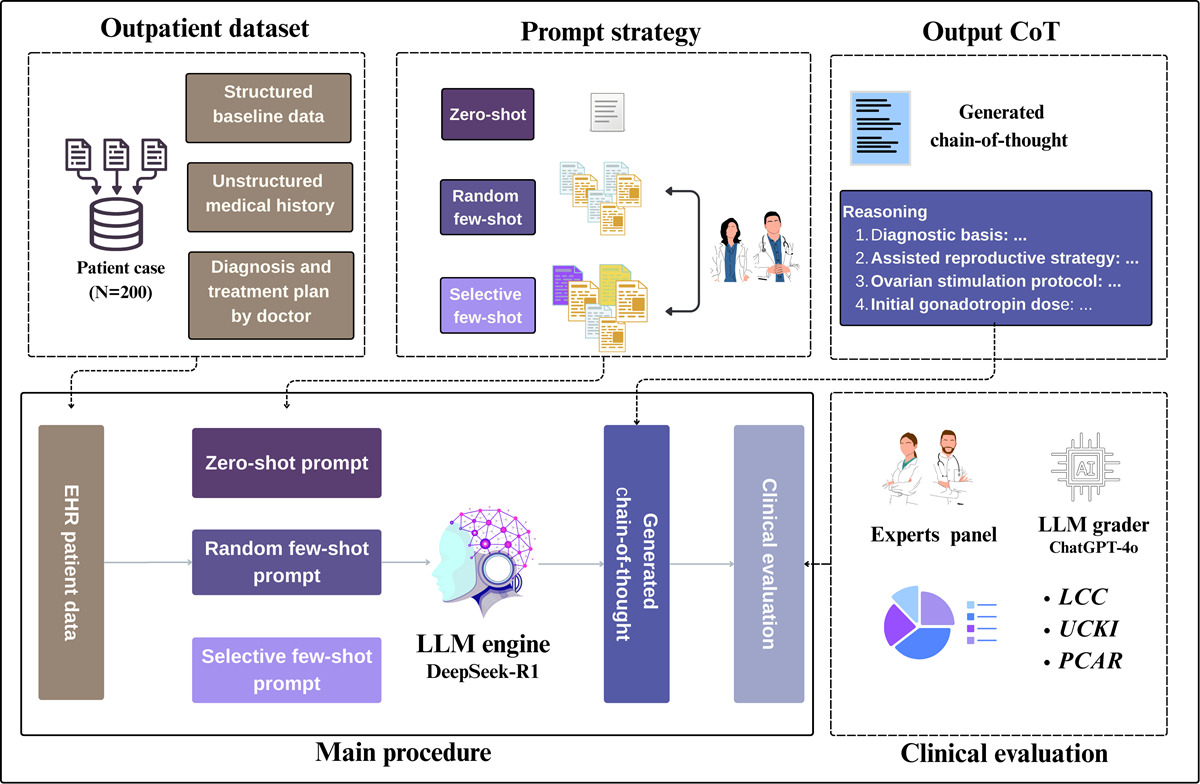
In recent years, medical artificial intelligence that can clearly explain the basis for diagnosis and treatment has been applied to assist clinical decision-making, but the development of such technology is limited by a critical bottleneck—the extreme scarcity of clinical reasoning chain data that details clinicians’ diagnostic and therapeutic thinking processes. Such data can fully demonstrate the reasoning path from illness analysis to treatment planning, serving as the core foundation for building trustworthy medical AI. However, manual curation is not only high-cost but also low-efficiency, which has largely hindered the advancement of medical AI in the field of assisted reproductive technology (ART). To address this challenge, the research team attempted to use large language models to generate such clinical reasoning chains in batches. This study focuses specifically on the ART scenario, with key efforts to verify the clinical reliability of model-generated content and the impact of different prompting methods on the quality of treatment recommendations, centering on the evaluation of ART treatment protocol selection and medication decision-making.
Liu D, Long Y, Zuoqiu S, et al. Reliability of Large Language Model Generated Clinical Reasoning in Assisted Reproductive Technology: Blinded Comparative Evaluation Study. J Med Internet Res. 2026;28:e85206. Published 2026 Jan 8. doi:10.2196/85206.
Dual Experimental Design: Exploring Core Issues Step by Step
With the core objectives of identifying the optimal prompting method and verifying the reliability of clinical reasoning, this study designed a logically rigorous experimental system. By unifying model parameters and conducting multi-dimensional evaluations, a complete analytical framework of “comparing prompting methods → verifying result credibility” was formed.
Experiment 1 focused on comparing the effects of three different prompting methods. The study selected DeepSeek-R1-671B, a large language model with strong reasoning capabilities, and based the research on 200 real-world ART cases covering three major categories (IVF, ICSI, PGT) and their common subtypes with complete clinical data. The first method was the no reference case method: only the diagnostic and therapeutic task and patient case were provided to the model to assess the quality of treatment recommendations generated solely by its inherent capabilities. The second was the random reference case method: in addition to the task and case, 5 simple IVF clinical cases were randomly added as references to observe the effect of general reference cases. The third was the curated reference case method: 6 high-quality clinical cases covering all major ART types were carefully selected as references, ensuring both clinical professionalism and comprehensive scenario coverage of the cases. The model was required to provide not only treatment recommendations but also detailed reasoning processes, and its responses were scored across three dimensions: coherence of reasoning logic, utilization rate of key clinical information, and clinical accuracy of treatment recommendations.
Experiment 2 was designed to verify the reliability of the evaluation results. Two clinicians with more than 10 years of clinical experience in ART were invited to conduct independent blinded scoring. Evaluation criteria were unified before scoring to avoid subjective bias. Meanwhile, the GPT-4o model was used as an AI evaluation tool to score according to the same criteria, and the differences between the evaluations by clinicians and AI were compared to ensure an objective and credible assessment of the quality of treatment recommendations.
Key Research Results: The Curated Reference Case Strategy Stands Out
Comparison of the Three Prompting Methods: High-Quality Reference Cases Are the Key to Improving Quality
Among the three methods, the curated reference case method achieved the best performance, with average scores of 4.56, 4.66 and 4.18 in the three core indicators (coherence of reasoning logic, utilization rate of key clinical information, and clinical accuracy of treatment recommendations), which were significantly superior to the other two methods (P<0.001). This advantage was evident across IVF, ICSI and PGT cases, and was particularly prominent in complex PGT cases.
The random reference case method performed slightly better than the no reference case method only in reasoning logic and information utilization, while there was little difference in the core indicator of clinical accuracy of treatment recommendations between the two (3.91 vs 3.85). The no reference case method yielded the lowest overall scores, with the generated clinical reasoning often suffering from missing key clinical information and incomplete reasoning processes.
Case Analysis: Exposing the Defects of Low-Quality Strategies
Taking complex preimplantation genetic testing for monogenic diseases (PGT-M) cases as an example, the clinical reasoning generated by the no reference case method and random reference case method had obvious clinical flaws: the background of the patient’s infertility diagnosis was not fully analyzed; the special requirement of avoiding embryonic genetic contamination in PGT cases was ignored when deciding whether to use ICSI technology; and when selecting the ovarian stimulation protocol, only safety was emphasized, without considering the individual conditions of the patient with low AMH levels and first-time ovulation induction. In contrast, the clinical reasoning generated by the curated reference case method featured complete clinical logic, without the aforementioned problems, and was highly consistent with clinicians’ clinical thinking.
Evaluation Comparison: AI Cannot Replace Human Experts for the Time Being
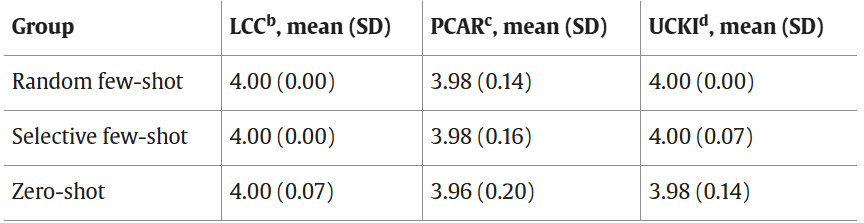
In terms of evaluation consistency, GPT-4o’s scores for different prompting strategies clustered in the range of 3.96–4.00 and failed to distinguish significant differences between the strategies, indicating certain limitations in its ability to identify clinically meaningful variations in reasoning quality. In comparison, the maximum scoring discrepancy rate between human experts was 12%, and the adjacent agreement rate reached 88%–100%, demonstrating a high level of consistency and also reflecting the important role of domain expert evaluation in the current stage.

Research Innovations and Limitations: Viewing Scientific Value Objectively
Core Innovations
This study proposes key prompting principles for generating high-quality clinical reasoning chains in the ART field—reference cases must simultaneously meet the requirements of clinical professionalism (aligning with clinical guidelines and evidence-based reasoning) and scenario comprehensiveness (covering all major ART types). It confirms that the efficacy of a prompting method depends on the quality and coverage of cases, rather than simply the quantity. Meanwhile, the parallel evaluation by clinicians and AI provides a practical reference for the automated evaluation of clinical diagnosis and treatment reasoning.
Notable Limitations
It should be noted that this study was based on single-center case data and only used a single generative model; thus, the applicability of the conclusions to different data sources and model architectures needs further verification. In addition, the curated reference case method and random reference case method differ in the quantity and depth of examples, and the relevant factors cannot be completely distinguished; the small number of cases for some subtypes may affect statistical stability; the performance of the AI evaluator may also be influenced by prompt design and model capabilities.
Clinical Significance and Future Outlook: Charting a Course for AI in Reproductive Medicine
Clinical Application Value
The scientifically designed curated reference case method enables large language models to generate high-quality clinical reasoning chains for ART, effectively alleviating the scarcity of high-quality clinical reasoning data. Such synthetic data is expected to be used in the training and optimization of clinical decision support systems in the future, helping clinicians quickly integrate patient information and accurately evaluate treatment protocols and medication strategies. In particular, it can provide support for primary medical institutions and improve the standardization level of ART diagnosis and treatment. At the same time, the study also reminds that automated evaluation tools should be used cautiously in clinical practice to avoid over-reliance.
Future Research Directions
Subsequent research will conduct multicenter and multi-model validation, and clarify the individual impacts of case quantity, professional depth and scenario coverage through special experiments; optimize prompting methods by combining authoritative ART clinical guidelines to further improve the clinical accuracy of model reasoning; and develop more sensitive automated evaluation tools targeting the evaluation needs of clinical diagnosis and treatment reasoning, to improve the clinical AI evaluation system.